Decoding#
Pynapple supports n-dimensional decoding from any neural modality.
For spike data, you can use decode_bayes, which implements Bayesian decoding using a Poisson distribution.
For any other type of data (and also for spike data), you can use decode_template, which implements a template matching algorithm.
Input to both decoding functions always includes:
tuning_curves, computed usingcompute_tuning_curves.data, neural activity as aTsGroup(spikes) orTsdFrame(smoothed counts or calcium activity or any other time series).epochs, to restrict decoding to certain intervals.sliding_window_size, uniform convolution window size (in number of bins) to smooth spike counts, only used if aTsGroupis passed (default isNone, for no smoothing). This is equivalent to using a sliding window with overlapping bins.bin_size, the size of the bins in which to count timestamps when data is aTsGroupobject.time_units, the units ofbin_size, defaulting to seconds.
Bayesian decoding#
When using Bayesian decoding, users can additionally set uniform_prior=False to use the occupancy as a prior over the feature distribution.
By default uniform_prior=True, and a uniform prior is used.
Important
Bayesian decoding should only be used with spike (TsGroup) or spike count (TsdFrame) data, as these can be assumed to follow a Poisson distribution!
1-dimensional Bayesian decoding#
First, we compute the tuning curves:
tuning_curves_1d = nap.compute_tuning_curves(
tsgroup,
feature,
bins=60,
range=(0, 2 * np.pi),
feature_names=["Circular feature"]
)
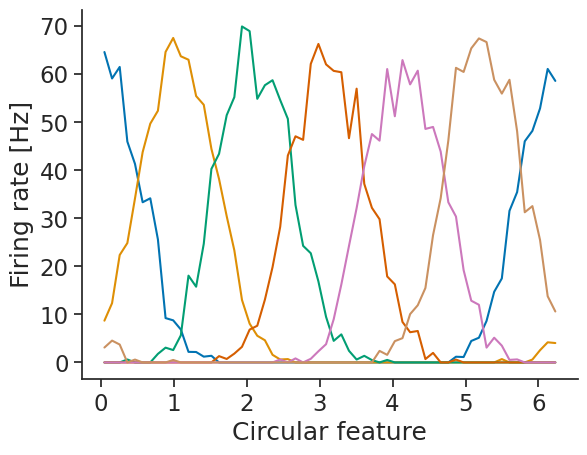
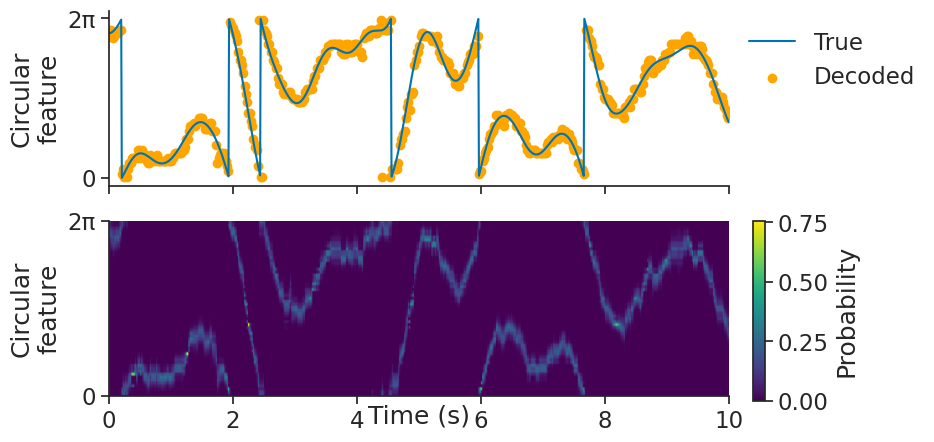
We can then use decode_bayes for Bayesian decoding.
We will use the sliding_window_size argument to additionally smooth the
spike counts with a uniform convolution window (i.e. use a sliding window), which often helps with decoding.
decoded, proba_feature = nap.decode_bayes(
tuning_curves=tuning_curves_1d,
data=tsgroup,
epochs=epochs,
sliding_window_size=4,
bin_size=0.02,
)
decoded is a Tsd object containing the decoded feature value.
proba_feature is a TsdFrame containing the probabilities of being in a particular feature bin over time.
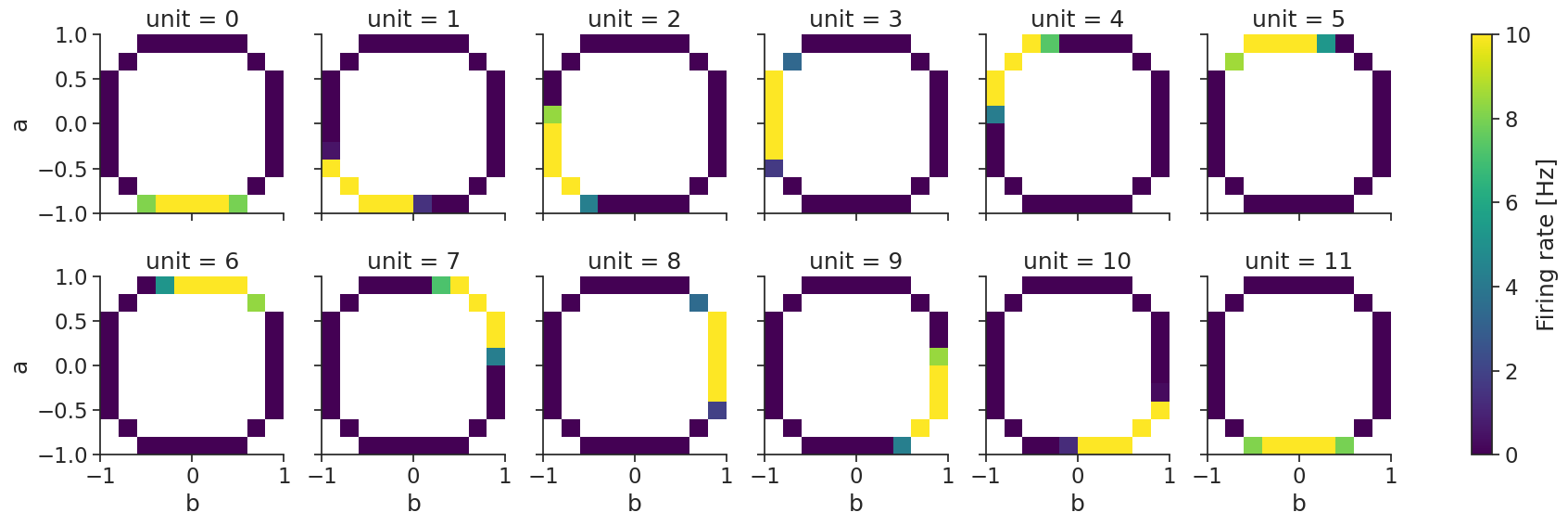
N-dimensional Bayesian decoding#
Decoding also works with multiple dimensions (here we show a 2D example).
First, we compute the tuning curves:
tuning_curves_2d = nap.compute_tuning_curves(
data=ts_group,
features=features, # containing 2 features
bins=10,
epochs=epochs,
range=[(-1.0, 1.0), (-1.0, 1.0)], # range can be specified for each feature
)
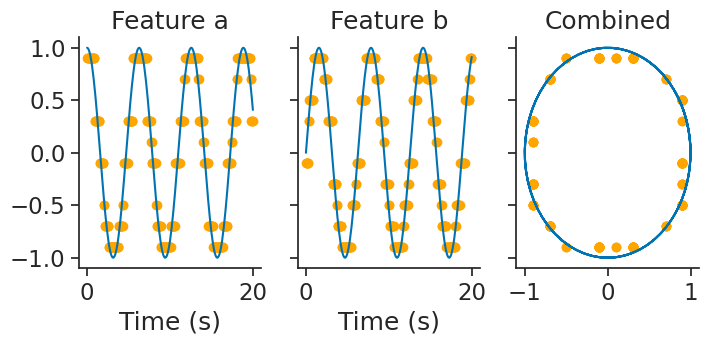
and then, decode_bayes again performs bayesian decoding:
decoded, proba_feature = nap.decode_bayes(
tuning_curves=tuning_curves_2d,
data=ts_group,
epochs=epochs,
sliding_window_size=2,
bin_size=0.05,
)
Template matching#
If you do not have spike data, or if you do not want to use the Poisson assumption, Pynapple also supports decoding using template matching, which makes no assumption on the modality of your data.
Instead of computing a probability distribution, compute_template computes a distance matrix between the samples and the tuning curves (smaller is better).
In addition to the default arguments, users can set metric to choose the used distance metric. By default metric="correlation".
1-dimensional template matching#
First, we compute the tuning curves (here we’ll use spikes as neural data):
tuning_curves_1d = nap.compute_tuning_curves(
tsgroup,
feature,
bins=61,
range=(0, 2 * np.pi),
feature_names=["Circular feature"]
)
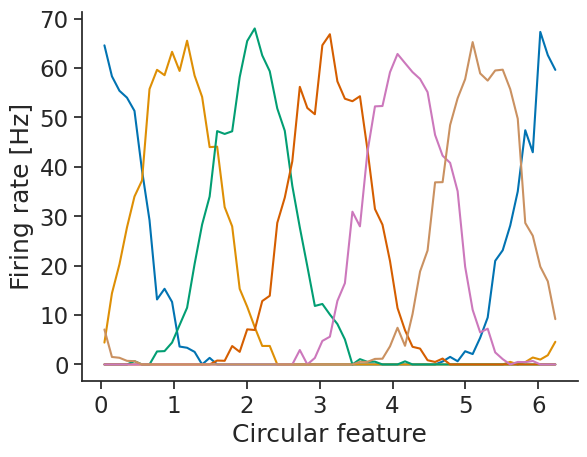
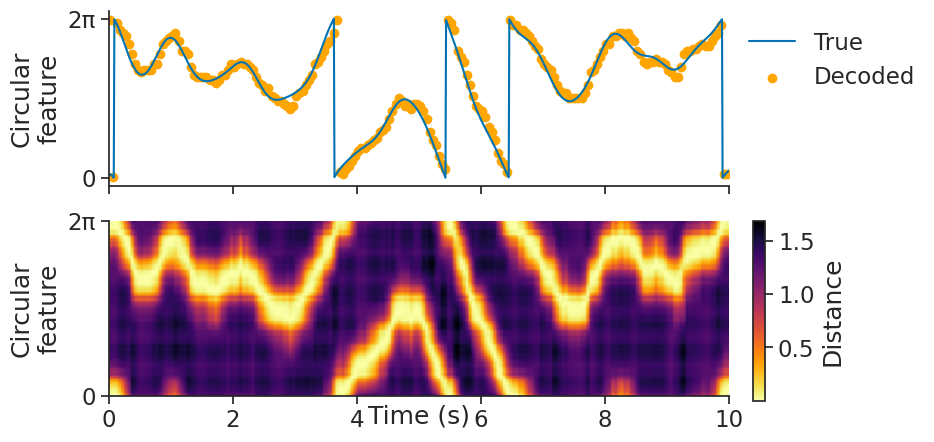
We can then use decode_template for template matching:
decoded, dist = nap.decode_template(
tuning_curves=tuning_curves_1d,
data=tsgroup,
epochs=epochs,
sliding_window_size=4,
bin_size=0.05,
metric="correlation"
)
decoded is a Tsd object containing the decoded feature value.
dist is a TsdFrame containing the distance matrix of every time bin with respect to the tuning curves.
N-dimensional template matching#
Template matching also works with multiple dimensions.
First, we compute the tuning curves (now let’s simulate calcium imaging in a TsdFrame):
tuning_curves_2d = nap.compute_tuning_curves(
data=tsdframe,
features=features, # containing 2 features
bins=10,
epochs=epochs,
range=[(-1.0, 1.0), (-1.0, 1.0)], # range can be specified for each feature
)
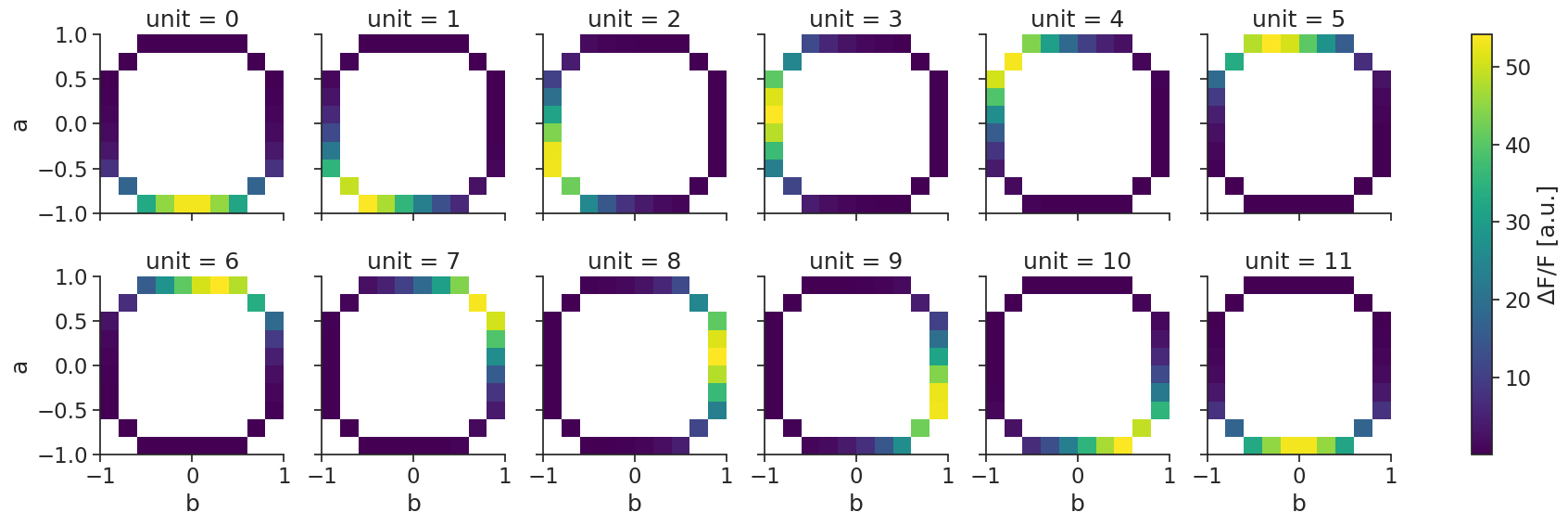
and then, decode_template again performs template matching:
decoded, dist = nap.decode_template(
tuning_curves=tuning_curves_2d,
data=tsdframe,
epochs=epochs,
bin_size=0.01,
metric="correlation"
)
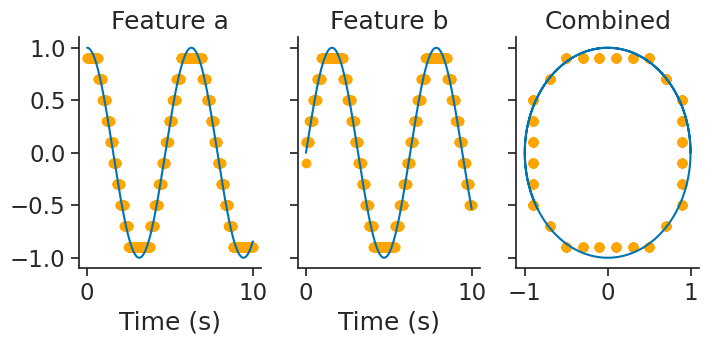
Take a look at the tutorial on calcium imaging for an application of template matching with real data and a comparison of various distance metrics!