pynapple.TsdFrame#
- class pynapple.TsdFrame(t, d=None, time_units='s', time_support=None, columns=None, load_array=True, metadata=None)[source]#
Bases:
_BaseTsd,_MetadataMixinColumn-based container for neurophysiological time series. A pandas.DataFrame can be passed directly.
- Parameters:
t (numpy.ndarray or pandas.DataFrame) – the time index t, or a pandas.DataFrame (if d is None)
d (numpy.ndarray) – The data
time_units (str, optional) – The time units in which times are specified (‘us’, ‘ms’, ‘s’ [default]).
time_support (IntervalSet, optional) – The time support of the TsdFrame object
columns (iterables) – Column names
load_array (bool, optional) – Whether the data should be converted to a numpy (or jax) array. Useful when passing a memory map object like zarr. Default is True. Does not apply if d is already a numpy array or a numpy memory map.
metadata (pd.DataFrame or dict, optional) – Metadata associated with data columns. Metadata names are pulled from DataFrame columns or dictionary keys. The length of the metadata should match the number of data columns. If a DataFrame is passed, the index should match the columns of the TsdFrame.
Examples
Initialize a TsdFrame:
>>> import pynapple as nap >>> import numpy as np >>> t = np.arange(100) >>> d = np.ones((100, 3)) >>> tsdframe = nap.TsdFrame(t=t, d=d) >>> tsdframe Time (s) 0 1 2 ---------- --- --- --- 0.0 1 1 1 1.0 1 1 1 2.0 1 1 1 3.0 1 1 1 4.0 1 1 1 5.0 1 1 1 6.0 1 1 1 ... 93.0 1 1 1 94.0 1 1 1 95.0 1 1 1 96.0 1 1 1 97.0 1 1 1 98.0 1 1 1 99.0 1 1 1 dtype: float64, shape: (100, 3)
Initialize a TsdFrame with column names:
>>> tsdframe = nap.TsdFrame(t=t, d=d, columns=['A', 'B', 'C']) >>> tsdframe Time (s) A B C ---------- --- --- --- 0.0 1 1 1 1.0 1 1 1 2.0 1 1 1 3.0 1 1 1 4.0 1 1 1 5.0 1 1 1 6.0 1 1 1 ... 93.0 1 1 1 94.0 1 1 1 95.0 1 1 1 96.0 1 1 1 97.0 1 1 1 98.0 1 1 1 99.0 1 1 1 dtype: float64, shape: (100, 3)
Initialize a TsdFrame with metadata:
>>> metadata = {"color": ["red", "blue", "green"], "depth": [1, 2, 3]} >>> tsdframe = nap.TsdFrame(t=t, d=d, columns=["A", "B", "C"], metadata=metadata) >>> tsdframe Time (s) A B C ---------- --- ---- ----- 0.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 2.0 1.0 1.0 1.0 3.0 1.0 1.0 1.0 4.0 1.0 1.0 1.0 5.0 1.0 1.0 1.0 6.0 1.0 1.0 1.0 ... 93.0 1.0 1.0 1.0 94.0 1.0 1.0 1.0 95.0 1.0 1.0 1.0 96.0 1.0 1.0 1.0 97.0 1.0 1.0 1.0 98.0 1.0 1.0 1.0 99.0 1.0 1.0 1.0 Metadata color red blue green depth 1 2 3 dtype: float64, shape: (100, 3)
Initialize a TsdFrame with a pandas DataFrame:
>>> import pandas as pd >>> data = pd.DataFrame(index=t, columns=["A", "B", "C"], data=d) >>> metadata = pd.DataFrame( ... index=["A", "B", "C"], ... columns=["color", "depth"], ... data=[["red", 1], ["blue", 2], ["green", 3]], ... ) >>> tsdframe = nap.TsdFrame(data, metadata=metadata) >>> tsdframe Time (s) A B C ---------- --- ---- ----- 0.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 2.0 1.0 1.0 1.0 3.0 1.0 1.0 1.0 4.0 1.0 1.0 1.0 5.0 1.0 1.0 1.0 6.0 1.0 1.0 1.0 ... 93.0 1.0 1.0 1.0 94.0 1.0 1.0 1.0 95.0 1.0 1.0 1.0 96.0 1.0 1.0 1.0 97.0 1.0 1.0 1.0 98.0 1.0 1.0 1.0 99.0 1.0 1.0 1.0 Metadata color red blue green depth 1 2 3 dtype: float64, shape: (100, 3)
- __init__(t, d=None, time_units='s', time_support=None, columns=None, load_array=True, metadata=None)[source]#
Methods
__init__(t[, d, time_units, time_support, ...])as_array()Return the data.
Convert the TsdFrame object to a pandas.DataFrame object.
as_units([units])Returns a DataFrame with time expressed in the desired unit.
bin_average(bin_size[, ep, time_units])Bin the data by averaging points within bin_size bin_size should be seconds unless specified.
convolve(array[, ep, trim])Return the discrete linear convolution of the time series with a one dimensional sequence.
copy()Copy the data, index and time support
count([bin_size, ep, time_units, dtype])Count occurences of events within bin_size or within a set of bins defined as an IntervalSet.
data()Return the data.
decimate(down[, order, filter_type, ep])Downsample the time series by an integer factor after an antialiasing filter.
derivative([ep])Computes the derivative of the time series with respect to time.
drop_info(key)Drop metadata based on metadata column name.
dropna([update_time_support])Drop every row containing NaNs.
end_time([units])The last time index in the time series object
find_peaks([epochs, return_prop])Find peaks based on peak properties.
find_support(min_gap[, time_units])find the smallest (to a min_gap resolution) IntervalSet containing all the times in the Tsd
get(start[, end, time_units])Slice the time series from start to end such that all the timestamps satisfy start<=t<=end.
get_info(key)Returns metadata based on metadata column name or index.
get_slice(start[, end, time_unit])Get a slice object from the time series data based on the start and end values such that all the timestamps satisfy start<=t<=end.
groupby(by[, get_group])Group pynapple object by metadata name(s).
groupby_apply(by, func[, input_key])Apply a function to each group in a grouped pynapple object.
in_interval(iset)Check which timestamps of the time series are within the intervals defined by an IntervalSet object
interpolate(ts[, ep, left, right])Wrapper of the numpy linear interpolation method.
restrict(iset)Restricts a time series object to a set of time intervals delimited by an IntervalSet object
restrict_info(key)Restrict metadata columns to a key or list of keys.
save(filename)Save TsdFrame object in npz format.
set_info([metadata])Add metadata information about the object.
smooth(std[, windowsize, time_units, ...])Smooth a time series with a gaussian kernel.
start_time([units])The first time index in the time series object
time_diff([align, epochs])Computes the differences between subsequent timestamps.
times([units])The time index of the object, returned as np.double in the desired time units.
to_numpy()Return the data as a numpy.ndarray.
to_trial_tensor(ep[, align, padding_value])Return trial-based tensor from an IntervalSet object.
value_from(data[, ep, mode])Replace the value with the closest value from Tsd/TsdFrame/TsdTensor argument
Attributes
The last time index in the time series
Returns a read-only version (copy) of the _metadata DataFrame
List of metadata column names.
The shape of the time series
The first time index in the time series
The time index of the time series
Data column names of the TsdFrame
An array of the time series data
The time index of the time series
Frequency of the time series (Hz) computed over the time support
The time support of the time series
Row index for metadata DataFrame.
- as_array()#
Return the data.
- Returns:
out – _
- Return type:
array-like
- as_dataframe()[source]#
Convert the TsdFrame object to a pandas.DataFrame object.
- Returns:
out – _
- Return type:
- as_units(units='s')[source]#
Returns a DataFrame with time expressed in the desired unit.
- Parameters:
units (str, optional) – (‘us’, ‘ms’, ‘s’ [default])
- Returns:
the series object with adjusted times
- Return type:
- bin_average(bin_size, ep=None, time_units='s')#
Bin the data by averaging points within bin_size bin_size should be seconds unless specified. If no epochs is passed, the data will be binned based on the time support.
- Parameters:
bin_size (float) – The bin size (default is second)
ep (None or IntervalSet, optional) – IntervalSet to restrict the operation
time_units (str, optional) – Time units of bin size (‘us’, ‘ms’, ‘s’ [default])
- Returns:
out – A Tsd object indexed by the center of the bins and holding the averaged data points.
- Return type:
Examples
This example shows how to bin data within bins of 0.1 second.
>>> import pynapple as nap >>> import numpy as np >>> tsd = nap.Tsd(t=np.arange(100), d=np.random.rand(100)) >>> bintsd = tsd.bin_average(0.1)
An epoch can be specified:
>>> ep = nap.IntervalSet(start = 10, end = 80, time_units = 's') >>> bintsd = tsd.bin_average(0.1, ep=ep)
And bintsd automatically inherit ep as time support:
>>> bintsd.time_support index start end 0 10 80 shape: (1, 2), time unit: sec.
- columns: Index#
Data column names of the TsdFrame
- convolve(array, ep=None, trim='both')#
Return the discrete linear convolution of the time series with a one dimensional sequence.
A parameter ep can control the epochs for which the convolution will apply. Otherwise, the convolution is made over the time support.
This function assume a constant sampling rate of the time series.
The only mode supported is full. The returned object is trimmed to match the size of the original object. The parameter trim controls which side the trimming operates. Default is ‘both’.
See the numpy documentation here : https://numpy.org/doc/stable/reference/generated/numpy.convolve.html
- Parameters:
array (array-like) – 1-D or 2-D array with kernel(s) to be used for convolution. First dimension is assumed to be time.
ep (None, optional) – The epochs to apply the convolution
trim (str, optional) – The side on which to trim the output of the convolution (‘left’, ‘right’, ‘both’ [default])
- Returns:
The convolved time series
- Return type:
- copy()#
Copy the data, index and time support
- count(bin_size=None, ep=None, time_units='s', dtype=None)[source]#
Count occurences of events within bin_size or within a set of bins defined as an IntervalSet. You can call this function in multiple ways :
1. tsd.count(bin_size=1, time_units = ‘ms’) -> Count occurence of events within a 1 ms bin defined on the time support of the object.
2. tsd.count(1, ep=my_epochs) -> Count occurent of events within a 1 second bin defined on the IntervalSet my_epochs.
3. tsd.count(ep=my_bins) -> Count occurent of events within each epoch of the intervalSet object my_bins
4. tsd.count() -> Count occurent of events within each epoch of the time support.
bin_size should be seconds unless specified. If bin_size is used and no epochs is passed, the data will be binned based on the time support of the object.
- Parameters:
bin_size (None or float, optional) – The bin size (default is second)
ep (None or IntervalSet, optional) – IntervalSet to restrict the operation
time_units (str, optional) – Time units of bin size (‘us’, ‘ms’, ‘s’ [default])
dtype (type, optional) – Data type for the count. Default is np.int64.
- Returns:
out – A Tsd object indexed by the center of the bins.
- Return type:
Examples
This example shows how to count timestamps within bins of 0.1 second.
>>> import pynapple as nap >>> import numpy as np; np.random.seed(42) >>> t = np.unique(np.sort(np.random.randint(0, 1000, 100))) >>> tsdframe = nap.TsdFrame(t=t, d=np.random.randn(len(t), 4), time_units='s') >>> tsdframe Time (s) 0 1 2 3 ---------- ---------- ---------- --------- ---------- 1.0 -2.17833 -1.0439 0.172694 0.324199 13.0 0.74586 -1.83658 0.564464 0.0255007 20.0 0.473193 0.659191 2.34075 1.07099 21.0 0.0964165 0.419102 -0.953028 -1.04787 34.0 -1.87568 -1.36678 0.636305 -0.906721 58.0 0.476043 1.30366 0.211587 0.597045 71.0 -0.896335 -0.111988 1.46894 -1.1239 ... 875.0 0.366909 0.209497 -0.875562 -0.234848 897.0 -0.987229 -0.491164 -1.20912 1.58914 931.0 -0.756906 -0.875079 -1.32561 -0.771205 942.0 -0.494893 -0.0494796 -0.645322 -1.60061 955.0 -1.51457 0.67966 -0.122789 0.648893 957.0 0.780275 0.15108 -1.23173 0.189585 975.0 1.3996 -0.447428 0.340615 -0.013778 dtype: float64, shape: (94, 4)
tsdframe_before is a timestamp table with data.
>>> ep = nap.IntervalSet(start = 0, end = 500, time_units = 's') >>> ep index start end 0 0 500 shape: (1, 2), time unit: sec.
ep is an IntervalSet object defining the epochs.
>>> bincount = tsdframe.count(10.0, ep=ep) >>> bincount Time (s) ---------- -- 5.0 1 15.0 1 25.0 2 35.0 1 45.0 0 55.0 1 ... 445.0 0 455.0 3 465.0 1 475.0 3 485.0 1 495.0 1 dtype: int64, shape: (50,) >>> bincount.time_support index start end 0 0 500 shape: (1, 2), time unit: sec.
bincount automatically inherits ep as time support.
- property d#
- data()#
Return the data.
- Returns:
out – _
- Return type:
array-like
- decimate(down, order=8, filter_type='iir', ep=None)#
Downsample the time series by an integer factor after an antialiasing filter.
As default, applies an antialiasing Chebyshev type I filter and downsample. The filter is a low pass-filter, if
filter_typeis set to “fir”, applies a 30 point filter with Hamming window.- Parameters:
down (int) – The down-sampling factor.
order (int, optional) – The order of the filter. Default is 8.
filter_type (literal, "iir" or "fir".) – The filter type. Default is “iir”.
ep (IntervalSet) – The epoch over which applying the decimate algorithm.
Example
>>> import pynapple as nap >>> import numpy as np >>> import matplotlib >>> matplotlib.use("Agg") >>> import matplotlib.pyplot as plt >>> noisy_data = np.random.rand(100) + np.sin(np.linspace(0, 2 * np.pi, 100)) >>> tsd = nap.Tsd(t=np.arange(100), d=noisy_data) >>> new_tsd = tsd.decimate(down=4) >>> plt.plot(tsd, color="k", label="original") [<matplotlib.lines.Line2D object at 0x...>] >>> plt.plot(new_tsd, color="r", marker="o", label="decimate") [<matplotlib.lines.Line2D object at 0x...>] >>> plt.plot(tsd[::4], color="g", marker="o", label="naive downsample") [<matplotlib.lines.Line2D object at 0x...>] >>> plt.legend() <matplotlib.legend.Legend object at 0x...> >>> plt.show()
(
Source code,png,hires.png,pdf)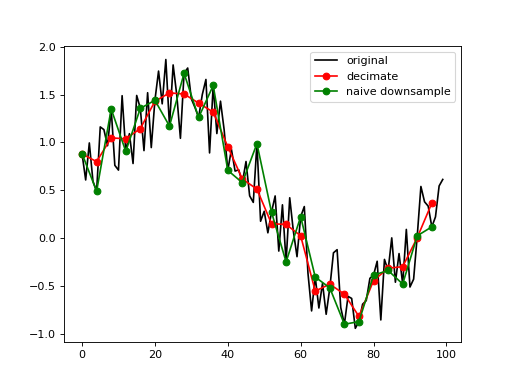
Downsample with decimate#
- derivative(ep=None)#
Computes the derivative of the time series with respect to time. Wraps numpy.gradient.
- Parameters:
ep (IntervalSet, optional) – The epochs to calculate derivatives. If None, the time support of Tsd is used.
- Returns:
The derivative of the time series.
- Return type:
Examples
>>> import pynapple as nap >>> import numpy as np >>> tsd = nap.Tsd(t=np.arange(5), d=np.arange(0, 10, 2)) >>> tsd_derivative = tsd.derivative() >>> tsd_derivative Time (s) ---------- -- 0 2 1 2 2 2 3 2 4 2 dtype: float64, shape: (5,)
- drop_info(key)[source]#
Drop metadata based on metadata column name. Operates in place.
Examples
>>> import pynapple as nap >>> import numpy as np >>> metadata = {"l1": [1, 2, 3], "l2": ["x", "x", "y"], "l3": [4, 5, 6]} >>> tsdframe = nap.TsdFrame(t=np.arange(5), d=np.ones((5, 3)), metadata=metadata) >>> print(tsdframe) Time (s) 0 1 2 ---------- --- --- --- 0.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 2.0 1.0 1.0 1.0 3.0 1.0 1.0 1.0 4.0 1.0 1.0 1.0 Metadata l1 1 2 3 l2 x x y ... ... ... ... dtype: float64, shape: (5, 3)
To drop a single metadata row:
>>> tsdframe.drop_info("l1") >>> tsdframe Time (s) 0 1 2 ---------- --- --- --- 0.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 2.0 1.0 1.0 1.0 3.0 1.0 1.0 1.0 4.0 1.0 1.0 1.0 Metadata l2 x x y l3 4 5 6 dtype: float64, shape: (5, 3)
To drop multiple metadata rows:
>>> tsdframe.drop_info(["l2", "l3"]) >>> tsdframe Time (s) 0 1 2 ---------- --- --- --- 0 1 1 1 1 1 1 1 2 1 1 1 3 1 1 1 4 1 1 1 dtype: float64, shape: (5, 3)
- dropna(update_time_support=True)#
Drop every row containing NaNs. By default, the time support is updated to start and end around the time points that are non NaNs. To change this behavior, you can set update_time_support=False.
- property end#
The last time index in the time series
- end_time(units='s')#
The last time index in the time series object
- Parameters:
units (str, optional) – (‘us’, ‘ms’, ‘s’ [default])
- Returns:
out – _
- Return type:
numpy.float64
- find_peaks(epochs=None, return_prop=False, *args, **kwargs)[source]#
Find peaks based on peak properties.
This function wraps
scipy.signal.find_peaks().- Parameters:
return_prop (bool, optional) – Whether to return the peak properties in the columns. See
scipy.signal.find_peaks()for the list of properties.height (number or ndarray or sequence, optional) – Required height of peaks. Either a number,
None, an array matching x or a 2-element sequence of the former. The first element is always interpreted as the minimal and the second, if supplied, as the maximal required height.threshold (number or ndarray or sequence, optional) – Required threshold of peaks, the vertical distance to its neighboring samples. Either a number,
None, an array matching x or a 2-element sequence of the former. The first element is always interpreted as the minimal and the second, if supplied, as the maximal required threshold.distance (number, optional) – Required minimal horizontal distance (>= 1) in samples between neighbouring peaks. Smaller peaks are removed first until the condition is fulfilled for all remaining peaks.
prominence (number or ndarray or sequence, optional) – Required prominence of peaks. Either a number,
None, an array matching x or a 2-element sequence of the former. The first element is always interpreted as the minimal and the second, if supplied, as the maximal required prominence.width (number or ndarray or sequence, optional) – Required width of peaks in samples. Either a number,
None, an array matching x or a 2-element sequence of the former. The first element is always interpreted as the minimal and the second, if supplied, as the maximal required width.wlen (int, optional) – Used for calculation of the peaks prominences, thus it is only used if one of the arguments prominence or width is given. See argument wlen in peak_prominences for a full description of its effects.
rel_height (float, optional) – Used for calculation of the peaks width, thus it is only used if width is given. See argument rel_height in peak_widths for a full description of its effects.
plateau_size (number or ndarray or sequence, optional) – Required size of the flat top of peaks in samples. Either a number,
None, an array matching x or a 2-element sequence of the former. The first element is always interpreted as the minimal and the second, if supplied as the maximal required plateau size.
- Returns:
peaks – The time points and values of the peaks per column. Peak properties are included in the entry columns if
return_prop=True.- Return type:
Examples
>>> import pynapple as nap >>> import numpy as np >>> times = np.arange(0, 10, 0.1) >>> tsdframe = nap.TsdFrame(t=times, d=np.stack([np.sin(times), np.cos(times)], axis=1)) >>> peaks = tsdframe.find_peaks() >>> peaks Index rate columns ------- ------- --------- 0 0.20202 0 1 0.10101 1 >>> peaks[0] Time (s) ---------- -------- 1.6 0.999574 7.9 0.998941 dtype: float64, shape: (2,)
You can set various requirements for finding peaks, for example a minimum width:
>>> peaks = tsdframe.find_peaks(width=21) >>> peaks Index rate columns ------- ------- --------- 0 0.10101 0 1 0.10101 1 >>> peaks[0] Time (s) ---------- -------- 7.9 0.998941 dtype: float64, shape: (1,)
If you further want the peak properties returned, you can pass return_prop=True:
>>> peaks = tsdframe.find_peaks(return_prop=True, width=21) >>> peaks Index rate columns ------- ------- --------- 0 0.10101 0 1 0.10101 1 >>> peaks[0] Time (s) peak_value prominences left_bases right_bases widths ... ---------- ------------ ------------- ------------ ------------- -------- ----- 7.9 0.998941 1.45648 47 99 25.9266 ... dtype: float64, shape: (1, 8)
- find_support(min_gap, time_units='s')#
find the smallest (to a min_gap resolution) IntervalSet containing all the times in the Tsd
- Parameters:
- Returns:
Description
- Return type:
- get(start, end=None, time_units='s')#
Slice the time series from start to end such that all the timestamps satisfy start<=t<=end. If end is None, only the timepoint closest to start is returned.
By default, the time support doesn’t change. If you want to change the time support, use the restrict function.
- get_info(key)[source]#
Returns metadata based on metadata column name or index.
If the metadata name does not contain special nor overlaps with class attributes, it can also be accessed as an attribute.
If the metadata name does not overlap with class-reserved keys, it can also be accessed as a key.
- Parameters:
key –
str: metadata column name or metadata index (for TsdFrame with string column names)
list of str: multiple metadata column names
- Returns:
The metadata information based on the key provided.
- Return type:
dict or np.array or Any (for single location)
- Raises:
IndexError – If the metadata index is not found.
Examples
>>> import pynapple as nap >>> import numpy as np >>> metadata = {"l1": [1, 2, 3], "l2": ["x", "x", "y"]} >>> tsdframe = nap.TsdFrame(t=np.arange(5), d=np.ones((5, 3)), metadata=metadata) >>> print(tsdframe) Time (s) 0 1 2 ---------- --- --- --- 0.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 2.0 1.0 1.0 1.0 3.0 1.0 1.0 1.0 4.0 1.0 1.0 1.0 Metadata l1 1 2 3 l2 x x y dtype: float64, shape: (5, 3)
To access a single metadata row (transposed to column):
>>> tsdframe.get_info("l1") 0 1 1 2 2 3 Name: l1, dtype: int64
To access multiple metadata rows (transposed to columns):
>>> tsdframe.get_info(["l1", "l2"]) l1 l2 0 1 x 1 2 x 2 3 y
To access metadata as an attribute:
>>> tsdframe.l1 0 1 1 2 2 3 Name: l1, dtype: int64
To access metadata as a key:
>>> tsdframe["l1"] 0 1 1 2 2 3 Name: l1, dtype: int64
Multiple metadata columns can be accessed as keys:
>>> tsdframe[["l1", "l2"]] l1 l2 0 1 x 1 2 x 2 3 y
- get_slice(start, end=None, time_unit='s')[source]#
Get a slice object from the time series data based on the start and end values such that all the timestamps satisfy start<=t<=end. If end is None, only the timepoint closest to start is returned.
By default, the time support doesn’t change. If you want to change the time support, use the restrict function.
This function is equivalent of calling the get method.
- Parameters:
- Returns:
slice – A slice determining the start and end indices, with unit step Slicing the array will be equivalent to calling get: ts[s].t == ts.get(start, end).t with s being the slice object.
- Return type:
- Raises:
If start or end is not a number. - If start is greater than end.
Examples
>>> import pynapple as nap >>> import numpy as np >>> tsdframe = nap.TsdFrame(t = [0, 1, 2, 3], d = np.random.randn(4, 3))
Slice over a range:
>>> tsdframe.get_slice(1.2, 2.6) slice(np.int64(2), np.int64(3), None) >>> tsdframe.get_slice(1.0, 2.0) slice(np.int64(1), np.int64(3), None)
Slice a single value:
>>> tsdframe.get_slice(1.2) slice(np.int64(1), np.int64(2), None) >>> tsdframe.get_slice(2.0) slice(np.int64(2), np.int64(3), None)
- groupby(by, get_group=None)[source]#
Group pynapple object by metadata name(s).
- Parameters:
- Returns:
Dictionary of object indices (dictionary values) corresponding to each group (dictionary keys), or pynapple object corresponding to ‘get_group’ if it has been supplied.
- Return type:
dict or pynapple object
- Raises:
ValueError – If metadata name does not exist.
Examples
>>> import pynapple as nap >>> import numpy as np >>> metadata = {"l1": [1, 2, 2], "l2": ["x", "x", "y"]} >>> tsdframe = nap.TsdFrame(t=np.arange(5), d=np.ones((5, 3)), metadata=metadata) >>> print(tsdframe) Time (s) 0 1 2 ---------- --- --- --- 0.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 2.0 1.0 1.0 1.0 3.0 1.0 1.0 1.0 4.0 1.0 1.0 1.0 Metadata l1 1 2 2 l2 x x y dtype: float64, shape: (5, 3)
Grouping by a single row:
>>> tsdframe.groupby("l2") {'x': Index([0, 1], dtype='int64'), 'y': Index([2], dtype='int64')}
Grouping by multiple rows:
>>> tsdframe.groupby(["l1","l2"]) {(1, 'x'): Index([0], dtype='int64'), (2, 'x'): Index([1], dtype='int64'), (2, 'y'): Index([2], dtype='int64')}
Filtering to a specific group using the output dictionary:
>>> groups = tsdframe.groupby("l2") >>> tsdframe[:,groups["x"]] Time (s) 0 1 ---------- --- --- 0.0 1.0 1.0 1.0 1.0 1.0 2.0 1.0 1.0 3.0 1.0 1.0 4.0 1.0 1.0 Metadata l1 1 2 l2 x x dtype: float64, shape: (5, 2)
Filtering to a specific group using the get_group argument:
>>> tsdframe.groupby("l2", get_group="x") Time (s) 0 1 ---------- --- --- 0.0 1.0 1.0 1.0 1.0 1.0 2.0 1.0 1.0 3.0 1.0 1.0 4.0 1.0 1.0 Metadata l1 1 2 l2 x x dtype: float64, shape: (5, 2)
- groupby_apply(by, func, input_key=None, **func_kwargs)[source]#
Apply a function to each group in a grouped pynapple object.
- Parameters:
func (function) – Function to apply to each group.
input_key (str or None, optional) – Input key that the grouped object will be passed as. If None, the grouped object will be passed as the first positional argument.
**func_kwargs (optional) – Additional keyword arguments to pass to the function. Any required positional arguments that are not the grouped object should be passed as keyword arguments.
- Returns:
Dictionary of results from applying the function to each group, where the keys are the group names and the values are the results.
- Return type:
Examples
>>> import pynapple as nap >>> import numpy as np >>> metadata = {"l1": [1, 2, 2], "l2": ["x", "x", "y"]} >>> tsdframe = nap.TsdFrame(t=np.arange(5), d=np.ones((5, 3)), metadata=metadata) >>> print(tsdframe) Time (s) 0 1 2 ---------- --- --- --- 0.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 2.0 1.0 1.0 1.0 3.0 1.0 1.0 1.0 4.0 1.0 1.0 1.0 Metadata l1 1 2 2 l2 x x y dtype: float64, shape: (5, 3)
Apply a numpy function:
>>> tsdframe.groupby_apply("l1", np.sum) {1: np.float64(5.0), 2: np.float64(10.0)}
Apply a custom function:
>>> tsdframe.groupby_apply("l1", lambda x: x.shape) {1: (5,), 2: (5, 2)}
Apply a function with additional arguments:
>>> tsdframe.groupby_apply("l1", np.sum, axis=0) {1: np.float64(5.0), 2: array([5., 5.])}
- in_interval(iset)[source]#
Check which timestamps of the time series are within the intervals defined by an IntervalSet object
- Parameters:
iset (IntervalSet) – the IntervalSet object
- Returns:
A Tsd of indicating which timestamps are within the intervals
- Return type:
Examples
>>> import pynapple as nap >>> import numpy as np >>> t = np.arange(100) >>> ep = nap.IntervalSet(start=0, end=50) >>> tsdframe = nap.TsdFrame(t=t, d=np.random.randn(len(t), 4)) >>> tsdframe.in_interval(ep) Time (s) ---------- ----- 0.0 True 1.0 True 2.0 True 3.0 True 4.0 True 5.0 True 6.0 True ... 93.0 False 94.0 False 95.0 False 96.0 False 97.0 False 98.0 False 99.0 False dtype: bool, shape: (100,)
- index: TsIndex#
The time index of the time series
- interpolate(ts, ep=None, left=None, right=None)#
Wrapper of the numpy linear interpolation method. See [numpy interpolate](https://numpy.org/doc/stable/reference/generated/numpy.interp.html) for an explanation of the parameters. The argument ts should be Ts, Tsd, TsdFrame, TsdTensor to ensure interpolating from sorted timestamps in the right unit,
- Parameters:
ts (Ts, Tsd, TsdFrame or TsdTensor) – The object holding the timestamps
ep (IntervalSet, optional) – The epochs to use to interpolate. If None, the time support of Tsd is used.
left (None, optional) – Value to return for ts < tsd[0], default is tsd[0].
right (None, optional) – Value to return for ts > tsd[-1], default is tsd[-1].
- property loc#
- property metadata#
Returns a read-only version (copy) of the _metadata DataFrame
- property metadata_columns#
List of metadata column names.
- metadata_index: ndarray | Index#
Row index for metadata DataFrame. This matches the index for TsGroup and IntervalSet, and the columns for TsdFrame.
- property ndim#
- restrict(iset)[source]#
Restricts a time series object to a set of time intervals delimited by an IntervalSet object
- Parameters:
iset (IntervalSet) – the IntervalSet object
- Returns:
Tsd object restricted to ep
- Return type:
Examples
>>> import pynapple as nap >>> import numpy as np; np.random.seed(42) >>> t = np.unique(np.sort(np.random.randint(0, 1000, 100))) >>> tsdframe_before = nap.TsdFrame(t=t, d=np.random.randn(len(t), 4), time_units='s') >>> tsdframe_before Time (s) 0 1 2 3 ---------- ---------- ---------- --------- ---------- 1.0 -2.17833 -1.0439 0.172694 0.324199 13.0 0.74586 -1.83658 0.564464 0.0255007 20.0 0.473193 0.659191 2.34075 1.07099 21.0 0.0964165 0.419102 -0.953028 -1.04787 34.0 -1.87568 -1.36678 0.636305 -0.906721 58.0 0.476043 1.30366 0.211587 0.597045 71.0 -0.896335 -0.111988 1.46894 -1.1239 ... 875.0 0.366909 0.209497 -0.875562 -0.234848 897.0 -0.987229 -0.491164 -1.20912 1.58914 931.0 -0.756906 -0.875079 -1.32561 -0.771205 942.0 -0.494893 -0.0494796 -0.645322 -1.60061 955.0 -1.51457 0.67966 -0.122789 0.648893 957.0 0.780275 0.15108 -1.23173 0.189585 975.0 1.3996 -0.447428 0.340615 -0.013778 dtype: float64, shape: (94, 4)
tsdframe_before is a timestamp table with data.
>>> ep = nap.IntervalSet(start = 0, end = 500, time_units = 's') >>> ep index start end 0 0 500 shape: (1, 2), time unit: sec.
ep is an IntervalSet object defining the epochs.
>>> tsdframe_after = tsdframe_before.restrict(ep) >>> tsdframe_after Time (s) 0 1 2 3 ---------- ---------- --------- ---------- ---------- 1.0 -2.17833 -1.0439 0.172694 0.324199 13.0 0.74586 -1.83658 0.564464 0.0255007 20.0 0.473193 0.659191 2.34075 1.07099 21.0 0.0964165 0.419102 -0.953028 -1.04787 34.0 -1.87568 -1.36678 0.636305 -0.906721 58.0 0.476043 1.30366 0.211587 0.597045 71.0 -0.896335 -0.111988 1.46894 -1.1239 ... 459.0 0.656797 -1.4359 -1.18327 0.494996 466.0 -0.16531 -0.687175 0.0683513 -0.409409 474.0 1.88955 -0.675805 -0.913413 -0.455033 475.0 -0.412762 0.595644 -1.99154 0.426026 476.0 -0.541285 0.776823 -0.0476437 0.518694 484.0 -0.391402 0.438023 1.66377 -0.739236 491.0 -0.107194 -0.486217 1.59298 -0.433942 dtype: float64, shape: (53, 4)
tsdframe_after is a timestamp table restricted to the epochs.
- restrict_info(key)[source]#
Restrict metadata columns to a key or list of keys.
Examples
>>> import pynapple as nap >>> import numpy as np >>> metadata = {"l1": [1, 2, 3], "l2": ["x", "x", "y"], "l3": [4, 5, 6]} >>> tsdframe = nap.TsdFrame(t=np.arange(5), d=np.ones((5, 3)), metadata=metadata) >>> print(tsdframe) Time (s) 0 1 2 ---------- --- --- --- 0.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 2.0 1.0 1.0 1.0 3.0 1.0 1.0 1.0 4.0 1.0 1.0 1.0 Metadata l1 1 2 3 l2 x x y ... ... ... ... dtype: float64, shape: (5, 3)
To restrict to multiple metadata rows:
>>> tsdframe.restrict_info(["l2", "l3"]) >>> tsdframe Time (s) 0 1 2 ---------- --- --- --- 0.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 2.0 1.0 1.0 1.0 3.0 1.0 1.0 1.0 4.0 1.0 1.0 1.0 Metadata l2 x x y l3 4 5 6 dtype: float64, shape: (5, 3)
To restrict to a single metadata row:
>>> tsdframe.restrict_info("l2") >>> tsdframe Time (s) 0 1 2 ---------- --- --- --- 0.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 2.0 1.0 1.0 1.0 3.0 1.0 1.0 1.0 4.0 1.0 1.0 1.0 Metadata l2 x x y dtype: float64, shape: (5, 3)
- save(filename)[source]#
Save TsdFrame object in npz format. The file will contain the timestamps, the data and the time support.
The main purpose of this function is to save small/medium sized time series objects. For example, you extracted several channels from your recording and filtered them. You can save the filtered channels as a npz to avoid reprocessing it.
You can load the object with nap.load_file. Keys are ‘t’, ‘d’, ‘start’, ‘end’, ‘type’ and ‘columns’ for columns names.
- Parameters:
filename (str) – The filename
Examples
>>> import pynapple as nap >>> import numpy as np >>> tsdframe = nap.TsdFrame(t=np.array([0., 1.]), d = np.array([[2, 3],[4,5]]), columns=['a', 'b']) >>> tsdframe.save("my_tsdframe.npz")
To load you file, you can use the nap.load_file function :
>>> tsdframe = nap.load_file("my_tsdframe.npz") >>> tsdframe Time (s) a b ---------- --- --- 0 2 3 1 4 5 dtype: int64, shape: (2, 2)
- Raises:
RuntimeError – If filename is not str, path does not exist or filename is a directory.
- set_info(metadata=None, **kwargs)[source]#
Add metadata information about the object. Metadata are saved as a dictionary.
If the metadata name does not contain special nor overlaps with class attributes, it can also be set using attribute assignment.
If the metadata name does not overlap with class-reserved keys, it can also be set using key assignment.
Metadata entries (excluding “rate” for TsGroup) are mutable and can be overwritten.
- Parameters:
metadata (pandas.DataFrame or dict or pandas.Series, optional) –
Object containing metadata information, where metadata names are extracted from column names (pandas.DataFrame), key names (dict), or index (pandas.DataFrame).
If a pandas.DataFrame is passed, the index must match the metadata index.
If a dictionary is passed, the length of each value must match the metadata index length.
A pandas.Series can only be passed if the object has a single interval.
**kwargs (optional) – Key-word arguments for setting metadata. Values can be either pandas.Series, numpy.ndarray, list or tuple, and must have the same length as the metadata index. If pandas.Series, the index must match the metadata index. If the object only has one index, non-iterable values are also accepted.
- Raises:
If metadata index does not match input index (pandas.DataFrame, pandas.Series) - If input array length does not match metadata length (numpy.ndarray, list, tuple)
RuntimeError – If the metadata argument is passed as a pandas.Series (for more than one metadata index), numpy.ndarray, list or tuple.
TypeError – If key-word arguments are not of type pandas.Series, tuple, list, or numpy.ndarray and cannot be set.
Examples
>>> import pynapple as nap >>> import numpy as np >>> tsdframe = nap.TsdFrame(t=np.arange(5), d=np.ones((5, 3)), columns=["a", "b", "c"])
To add metadata with a pandas.DataFrame:
>>> import pandas as pd >>> metadata = pd.DataFrame(index=tsdframe.columns, data=["red", "blue", "green"], columns=["color"]) >>> tsdframe.set_info(metadata) >>> tsdframe Time (s) a b c ---------- --- ---- ----- 0.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 2.0 1.0 1.0 1.0 3.0 1.0 1.0 1.0 4.0 1.0 1.0 1.0 Metadata color red blue green dtype: float64, shape: (5, 3)
To add metadata with a dictionary:
>>> metadata = {"xpos": [10, 20, 30]} >>> tsdframe.set_info(metadata) >>> tsdframe Time (s) a b c ---------- --- ---- ----- 0.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 2.0 1.0 1.0 1.0 3.0 1.0 1.0 1.0 4.0 1.0 1.0 1.0 Metadata color red blue green xpos 10 20 30 dtype: float64, shape: (5, 3)
To add metadata with a keyword arument (pd.Series, numpy.ndarray, list or tuple):
>>> ypos = pd.Series(index=tsdframe.columns, data = [10, 10, 10]) >>> tsdframe.set_info(ypos=ypos) >>> tsdframe Time (s) a b c ---------- --- ---- ----- 0.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 2.0 1.0 1.0 1.0 3.0 1.0 1.0 1.0 4.0 1.0 1.0 1.0 Metadata color red blue green xpos 10 20 30 ... ... ... ... dtype: float64, shape: (5, 3)
To add metadata as an attribute:
>>> tsdframe.label = ["a", "b", "c"] >>> tsdframe Time (s) a b c ---------- --- ---- ----- 0.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 2.0 1.0 1.0 1.0 3.0 1.0 1.0 1.0 4.0 1.0 1.0 1.0 Metadata color red blue green xpos 10 20 30 ... ... ... ... dtype: float64, shape: (5, 3)
To add metadata as a key:
>>> tsdframe["region"] = ["M1", "M1", "M2"] >>> tsdframe Time (s) a b c ---------- --- ---- ----- 0.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 2.0 1.0 1.0 1.0 3.0 1.0 1.0 1.0 4.0 1.0 1.0 1.0 Metadata color red blue green xpos 10 20 30 ... ... ... ... dtype: float64, shape: (5, 3)
Metadata can be overwritten:
>>> tsdframe.set_info(label=["x", "y", "z"]) >>> tsdframe Time (s) a b c ---------- --- ---- ----- 0.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 2.0 1.0 1.0 1.0 3.0 1.0 1.0 1.0 4.0 1.0 1.0 1.0 Metadata color red blue green xpos 10 20 30 ... ... ... ... dtype: float64, shape: (5, 3)
- property shape#
The shape of the time series
- property size#
- smooth(std, windowsize=None, time_units='s', size_factor=100, norm=True)#
Smooth a time series with a gaussian kernel.
std is the standard deviation of the gaussian kernel in units of time. If only std is passed, the function will compute the standard deviation and size in number of time points automatically based on the sampling rate of the time series. For example, if the time series tsd has a sample rate of 100 Hz and std is 50 ms, the standard deviation will be converted to an integer through tsd.rate * std = int(100 * 0.05) = 5.
If windowsize is None, the function will select a kernel size as 100 times the std in number of time points. This behavior can be controlled with the parameter size_factor.
norm set to True normalizes the gaussian kernel to sum to 1.
In the following example, a time series tsd with a sampling rate of 100 Hz is convolved with a gaussian kernel. The standard deviation is 0.05 second and the windowsize is 2 second. When instantiating the gaussian kernel from scipy, it corresponds to parameters M = 200 and std=5
>>> tsd.smooth(std=0.05, windowsize=2, time_units='s', norm=False)
This line is equivalent to :
>>> from scipy.signal.windows import gaussian >>> kernel = gaussian(M = 200, std=5) >>> tsd.convolve(window)
It is generally a good idea to visualize the kernel before applying any convolution.
See the scipy documentation for the [gaussian window](https://docs.scipy.org/doc/scipy/reference/generated/scipy.signal.windows.gaussian.html)
- Parameters:
std (Number) – Standard deviation in units of time
windowsize (Number) – Size of the gaussian window in units of time.
time_units (str, optional) – The time units in which std and windowsize are specified (‘us’, ‘ms’, ‘s’ [default]).
size_factor (int, optional) – How long should be the kernel size as a function of the standard deviation. Default is 100. Bypassed if windowsize is used.
norm (bool, optional) – Whether to normalized the gaussian kernel or not. Default is True.
- Returns:
Time series convolved with a gaussian kernel
- Return type:
- property start#
The first time index in the time series
- start_time(units='s')#
The first time index in the time series object
- Parameters:
units (str, optional) – (‘us’, ‘ms’, ‘s’ [default])
- Returns:
out – _
- Return type:
numpy.float64
- property t#
The time index of the time series
- time_diff(align='center', epochs=None)[source]#
Computes the differences between subsequent timestamps.
- Parameters:
align (str, optional) –
- Determines the time index of the resulting time differences:
”start” : the start of the interval between two timestamps.
”center” [default]: the center of the interval between two timestamps.
”end” : the end of the interval between two timestamps.
epochs (IntervalSet, optional) – The epochs on which differences are computed. If None, the time support of the input is used.
- Returns:
The time differences.
- Return type:
Examples
>>> import pynapple as nap >>> import numpy as np >>> tsdframe = nap.TsdFrame(t=[1, 3, 5, 6, 8, 12], d=np.ones((6, 2))) >>> epochs = nap.IntervalSet(start=2, end=9, time_units='s') >>> tsd_time_diffs = tsdframe.time_diff(align="center", epochs=epochs) >>> tsd_time_diffs Time (s) ---------- -- 4 2 5.5 1 7 2 dtype: float64, shape: (3,)
- time_support: IntervalSet#
The time support of the time series
- times(units='s')#
The time index of the object, returned as np.double in the desired time units.
- Parameters:
units (str, optional) – (‘us’, ‘ms’, ‘s’ [default])
- Returns:
out – the time indexes
- Return type:
- to_numpy()#
Return the data as a numpy.ndarray.
Mostly useful for matplotlib plotting when calling plot(tsd).
- to_trial_tensor(ep, align='start', padding_value=nan)#
Return trial-based tensor from an IntervalSet object. The shape of the tensor array is (shape of time series, number of trials, number of time points)
The align parameter controls how the time series are aligned. If align=”start”, the time series are aligned to the start of each trial. If align=”end”, the time series are aligned to the end of each trial.
If trials have uneven durations, the returned array is padded. The parameter padding_value determine which value is used to pad the array. Default is NaN.
- Parameters:
ep (IntervalSet) – Epochs holding the trials. Each interval can be of unequal size.
align (str, optional) – How to align the time series (‘start’ [default], ‘end’)
padding_value (Number, optional) – How to pad the array if unequal intervals. Default is np.nan.
- Return type:
Examples
>>> import pynapple as nap >>> import numpy as np >>> tsdframe = nap.TsdFrame(t=np.arange(100), d=np.arange(200).reshape(2,100).T) >>> ep = nap.IntervalSet(start=np.arange(20, 100, 20), end=np.arange(20, 100, 20) + np.arange(2, 10, 2)) >>> print(ep) index start end 0 20 22 1 40 44 2 60 66 3 80 88 shape: (4, 2), time unit: sec.
Create a trial-based tensor by slicing tsdframe for each interval of ep.
>>> tensor = tsdframe.to_trial_tensor(ep) >>> tensor array([[[ 20., 21., 22., nan, nan, nan, nan, nan, nan], [ 40., 41., 42., 43., 44., nan, nan, nan, nan], [ 60., 61., 62., 63., 64., 65., 66., nan, nan], [ 80., 81., 82., 83., 84., 85., 86., 87., 88.]], [[120., 121., 122., nan, nan, nan, nan, nan, nan], [140., 141., 142., 143., 144., nan, nan, nan, nan], [160., 161., 162., 163., 164., 165., 166., nan, nan], [180., 181., 182., 183., 184., 185., 186., 187., 188.]]])
- value_from(data, ep=None, mode='closest')[source]#
Replace the value with the closest value from Tsd/TsdFrame/TsdTensor argument
- Parameters:
data (Tsd, TsdFrame or TsdTensor) – The object holding the values to replace.
ep (IntervalSet (optional)) – The IntervalSet object to restrict the operation. If None, the time support of the tsd input object is used.
mode (literal, either 'closest', 'before', 'after') – If closest, replace value with value from Tsd/TsdFrame/TsdTensor, if before gets the first value before, if after the first value after.
- Returns:
out – Object with the new values
- Return type:
Examples
In this example, the tsdframe object will receive the closest values in time from a tsd.
>>> import pynapple as nap >>> import numpy as np; np.random.seed(42) >>> t = np.unique(np.sort(np.random.randint(0, 1000, 100))) # random times >>> tsdframe = nap.TsdFrame(t=t, d=np.random.randn(len(t), 3), time_units='s') >>> tsdframe Time (s) 0 1 2 ---------- ---------- ---------- --------- 1.0 -2.17833 -1.0439 0.172694 13.0 0.324199 0.74586 -1.83658 20.0 0.564464 0.0255007 0.473193 21.0 0.659191 2.34075 1.07099 34.0 0.0964165 0.419102 -0.953028 58.0 -1.04787 -1.87568 -1.36678 71.0 0.636305 -0.906721 0.476043 ... 875.0 -0.9812 -1.23823 -0.824651 897.0 1.95128 -0.0400851 0.529436 931.0 -0.183892 -0.0900786 -0.50588 942.0 0.050744 0.4946 1.67831 955.0 -1.87447 1.61082 0.52796 957.0 -0.367763 -0.547723 1.04368 975.0 0.228979 -1.53407 0.36307 dtype: float64, shape: (94, 3)
tsdframe is a timestamp table with values.
>>> tsd_from = nap.Tsd(t=np.arange(0,1000), d=np.random.choice([1,2,3], 1000), time_units='s') >>> tsd_from Time (s) ---------- -- 0.0 3 1.0 1 2.0 3 3.0 1 4.0 3 5.0 1 6.0 2 ... 993.0 1 994.0 2 995.0 3 996.0 1 997.0 3 998.0 2 999.0 3 dtype: int64, shape: (1000,)
tsd_from contains values, for example the tracking data.
>>> ep = nap.IntervalSet(start = 0, end = 500, time_units = 's') >>> ep index start end 0 0 500 shape: (1, 2), time unit: sec.
An epoch can be passed to restrict the operation.
>>> tsd_after = tsdframe.value_from(tsd_from, ep, mode='closest') >>> tsd_after Time (s) ---------- -- 1.0 1 13.0 3 20.0 3 21.0 2 34.0 1 58.0 3 71.0 3 ... 459.0 2 466.0 2 474.0 3 475.0 1 476.0 2 484.0 2 491.0 3 dtype: int64, shape: (53,)
tsd_after is the same length as ts when restricted to ep.
>>> print(len(tsdframe.restrict(ep)), len(tsd_after)) 53 53
{kind=link}
{kind=link}